
MaXTron is a simple yet effective unified meta-architecture for video segmentation.
It enriches existing clip-level segmenters by improving both the within-clip and cross-clip tracking ability.
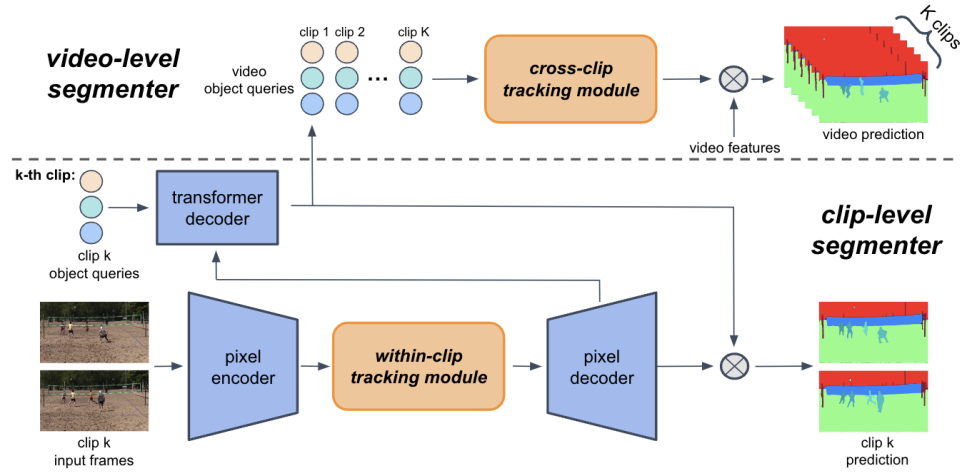
Video panoptic segmentation requires consistently segmenting (for both 'thing' and 'stuff' classes) and tracking objects in a video over time. In this work, we present MaXTron, a general framework that exploits Mask XFormer with Trajectory Attention to tackle the task. MaXTron enriches an off-the-shelf mask transformer by leveraging trajectory attention. The deployed mask transformer takes as input a short clip consisting of only a few frames and predicts the clip-level segmentation. To enhance the temporal consistency, MaXTron employs within-clip and cross-clip tracking modules, efficiently utilizing trajectory attention. Originally designed for video classification, trajectory attention learns to model the temporal correspondences between neighboring frames and aggregates information along the estimated motion paths. However, it is nontrivial to directly extend trajectory attention to the per-pixel dense prediction tasks due to its quadratic dependency on input size. To alleviate the issue, we propose to adapt the trajectory attention for both the dense pixel features and object queries, aiming to improve the shortterm and long-term tracking results, respectively. Particularly, in our within-clip tracking module, we propose axial-trajectory attention that effectively computes the trajectory attention for tracking dense pixels sequentially along the heightand width-axes. The axial decomposition significantly reduces the computational complexity for dense pixel features. In our cross-clip tracking module, since the object queries in mask transformer are learned to encode the object information, we are able to capture the long-term temporal connections by applying trajectory attention to object queries, which learns to track each object across different clips. Without bells and whistles, MaXTron demonstrates state-of-the-art performances on video segmentation benchmarks.
@misc{he2023maxtron,
title={MaXTron: Mask Transformer with Trajectory Attention for Video Panoptic Segmentation},
author={Ju He and Qihang Yu and Inkyu Shin and Xueqing Deng and Xiaohui Shen and Alan Yuille and Liang-Chieh Chen},
year={2023},
eprint={2311.18537},
archivePrefix={arXiv},
primaryClass={cs.CV}
}